O evento já encerrou...
8° Bootcamp Data Engineering com AWS & Cia
8° Bootcamp Data Engineering com AWS & Cia
03 jan - 2023 • 19:00 > 26 jan - 2023 • 22:00
8° Bootcamp Data Engineering com AWS & Cia
03 jan - 2023 • 19:00 > 26 jan - 2023 • 22:00
Descrição do evento
Estamos com a 8°edição do Bootcamp Data Engineering com AWS & Cia Online ao Vivo e temos o prazer em te convidar para participar entre os dias 03 a 26 de Janeiro de 2023, a partir das 19h (terças e quintas), deste super evento para acompanhar a construção de uma moderna arquitetura de dados de alta performance, baixo custo de armazenamento e processamento para análises de grandes volumes de dados.
Esta é uma ótima oportunidade para colocar a sua carreira num próximo nível de classe mundial logo no início do ano, pois apesar do uso de nuvem no Brasil já ser uma realidade há algum tempo, o uso de tecnologias e serviços voltados ao desenvolvimento de uma solução de Analytics, ainda está em estágios iniciais, porém já é algo bastante utilizado em empresas lá fora e que a demanda só cresce por aqui e já pagando ótimos salários.
Neste bootcamp o participante acompanhará o desenvolvimento completo de uma solução para Data Lake House, que reúne o melhor de 2 mundos, o Data Lake e o Data Warehouse, através de uma série de exercícios totalmente práticos desenvolvidos pelo facilitador que abordará a construção de um moderno pipeline de dados para um Data Lake em S3 usando uma das mais promissoras ferramentas do guarda-chuva Apache, o Apache Hop para o desenvolvimento dos pipelines de transformação de dados de forma visual, sem codificação, apoiando-se na ferramenta Apache Airflow para a gestão das execuções agendadas desses pipelines como também a utilização dos serviços AWS como o Glue, Athena e Redshift para a criação de uma camada de sustentação de dados para Analytics, o Data Warehouse, onde através de ferramentas de BI, como o Power BI e AWS Quicksight, sejam entregues as informações aos usuários de negócios num ambiente mais ágil, moderno, robusto e escalável.
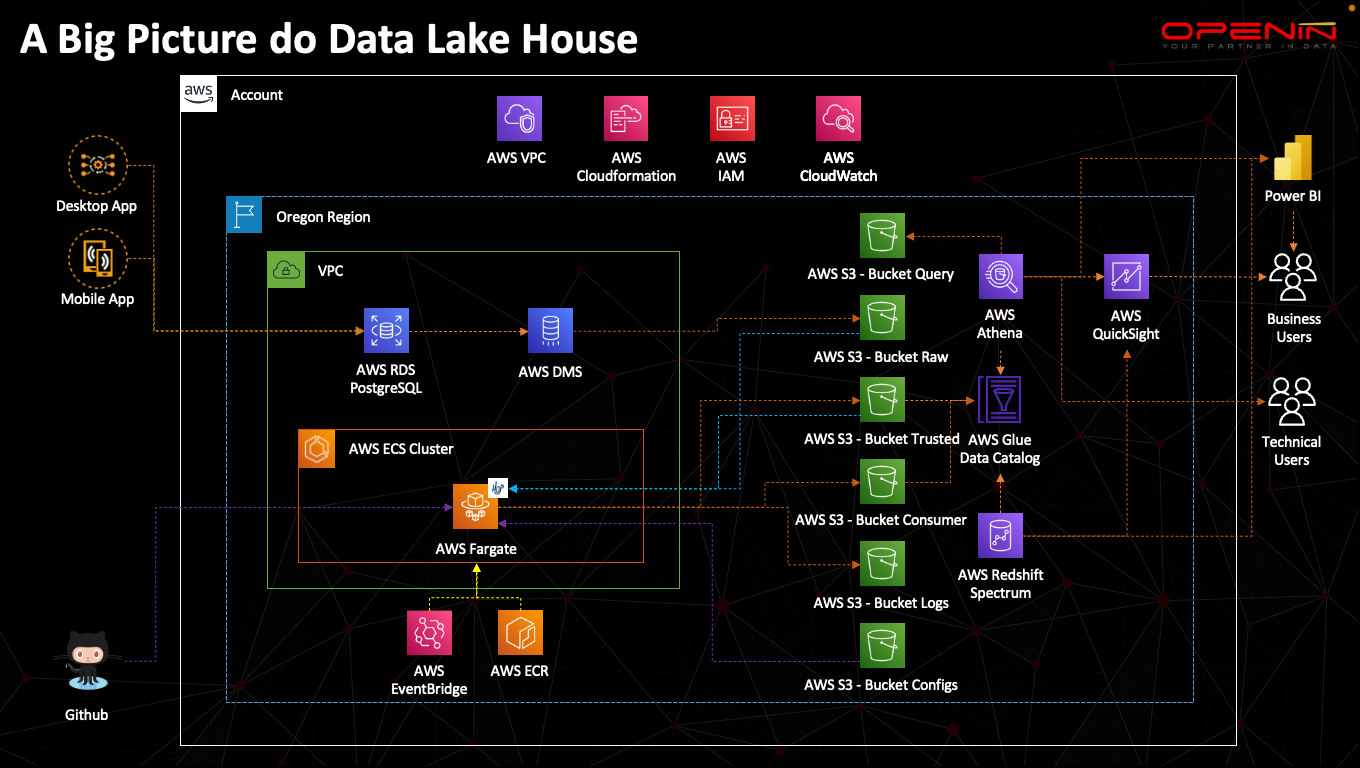
Imagem ilustrativa da arquitetura a ser desenvolvida
Toda a construção da arquitetura da imagem acima, será feita através do conceito de IaC (Infrastructure as Code ou Infraestrutura como Código) que junto ao conceito de CI/CD vem permeando a cultura DevOps nas empresas e ter essas duas práticas dentro do dia a dia de um engenheiro de dados é fundamental.
Confira abaixo, a Live que foi realizada em 21/12, ela oferece uma boa ideia de como será este treinamento:
Objetivos da aprendizagem
• Capacitar os participantes a trabalharem com uma pilha tecnológica moderna;
• Criar toda a infraestrutura via IaC e CI/CD;
• Gerar conhecimento aos participantes para além da criação de uma solução desta, do zero, mas também podendo migrar soluções on-premises para cloud;
• Criar um ambiente de Data Lake segmentado por contextos para apoiar entregas de Analytics;
• Utilizar as principais ferramentas da AWS para Analytics;
• Estruturar um Data Warehouse apoiado em dados de um Data Lake;
• Utilizar uma modelagem de dados que permita o upsert em arquivos S3;
• Desenvolver processos de ingestão baseados em CDC e transformação de dados com mais produtividade, sem a necessidade de codificação (no-code/low-code);
• Controlar as execuções dos pipelines de dados de forma mais profissional;
• Utilizar das melhores práticas para ter um consumo mais econômico e seguro na AWS; e
• Conectar ferramentas de Data Viz nessa moderna arquitetura de dados.
Ferramentas e serviços utilizados
• AWS VPC;
• AWS Cloudformation;
• AWS IAM;
• AWS CloudWatch;
• AWS RDS (PostgreSQL);
• AWS DMS;
• AWS EC2;
• AWS S3;
• AWS Glue;
• AWS Athena;
• AWS Redshift Spectrum;
• AWS ECS;
• AWS ECR;
• AWS Fargate;
• AWS EventBridge;
• AWS QuickSight;
• AWS CLI;
• Apache Hop;
• Apache Airflow;
• Docker;
• Github;
• Github Actions; e
• Power BI Desktop.
Requisitos
• Ser um profissional da área de tecnologia ou formado em áreas ligadas a TI; e
• Não há necessidade de conhecimento prévio em nenhuma tecnologia ou serviço que iremos utilizar.
Pré-requisitos
• Criar uma conta nova (necessário ter cartão de crédito) na AWS para poder usufruir de alguns dos serviços necessários ao bootcamp na modalidade gratuita.
Público Alvo
• Profissionais iniciando na carreira de Engenharia de Dados;
• Profissionais envolvidos em projetos de Desenvolvimento de Software com interesse em Engenharia de Dados; e
• Profissionais já envolvidos em projetos de Desenvolvimento de Data Lake, Data Warehouse, Data Viz, Data Science e Business Intelligence.
Casos de sucesso
• A OLX reduziu custos e tempo de acesso ao mercado por meio da implantação do Athena em toda a organização
• A Atlassian criou um data lake de autoatendimento usando o Amazon Athena e outros serviços do AWS Analytics
• Como FINRA opera análises em escala de PB em data lakes com o Amazon Athena (AWS re:Invent 2020)
Benefícios da aprendizagem
• O participante terá o entendimento completo para atuar como Engenheiro de Dados e construir via AWS e Cia, um pipeline de dados, a partir do zero para uma moderna arquitetura de dados para Analytics, apoiada por um Data Warehouse dentro do Data Lake em S3, solução esta conhecida como Data Lake House;
• É parte integrante desta proposta, o acesso as aulas gravadas dos encontros em nossa plataforma EaD por 365 dias, liberadas já no dia seguinte aos encontros;
• Integra também esta proposta a participação vitalícia do participante em nossa comunidade Data Engineering for Analytics com AWS & Cia no Telegram que já conta com +100 membros onde poderá realizar networking e participar de encontros virtuais com outros membros da comunidade; e
• No grupo do Telegram também poderá obter suporte técnico referente ao conteúdo do bootcamp e mentoria sobre outras possibilidades de uso.
Idioma
• Ministrado em português e Material didático em formato eletrônico em português (Brasil).
Conteúdo Programático
• Os escopos dos ambientes de desenvolvimento e produção;
• Requisitos que norteiam uma solução de Big Data;
• O que é uma solução de Data Lake House;
• Fundamentos AWS;
• Usando Amazon Virtual Private Cloud (AWS VPC) default para segmentar a rede do ambiente de desenvolvimento;
• Usando Amazon Elastic Compute Cloud (AWS EC2) para o ambiente de desenvolvimento;
• Criando o repositório para versionamento e deploy para o curso - DevOps com Git e Github;
• Usando Amazon Cloudformation (AWS Cloudformation) para criar e gerenciar a infraestrutura da arquitetura com IaC (Infraestrutura como código);
• Usando Amazon Virtual Private Cloud (AWS VPC) via Cloudformation para segmentar a rede do ambiente de produção;
• Configuração e uso do IAM para o gerenciamento de identidade e acesso ao Data Lake e ao Data Viz;
• Usando o Github Actions para deployar (CI/CD) a infraestrutura do curso;
• Elaborando o template Cloudformation para:
○ a base de dados PostgreSQL em RDS e deployando via Github Actions;
○ os buckets em S3 e deployando-os via Github Actions;
○ as tasks DMS que realizarão a ingestão no Data Lake via CDC e deployando-as via Github Actions;
○ o catálogo de dados das tabelas dos bancos ODS e Data Warehouse no Glue e deployando via Github Actions;
○ o serviço de query do Athena que permitirá executar queries nos bancos do Glue e deployando via Github Actions;
• Configuração do ambiente de desenvolvimento do Apache Hop para o desenvolvimento dos workflows/pipelines;
○ Repositório do projeto;
○ Variáveis de ambiente;
○ Ferramentas Apache Hop;
○ Credencial AWS;
○ Arquivos em formato aberto Parquet;
○ Modelagem de dados contemplando o Table Format (upserts em S3);
○ Conexões com o banco postgreSQL, Athena e Redshift;
○ Desenvolvimento dos processos (workflows/pipelines) ETL de transformação dos dados nas áreas segmentadas do Data Lake com o Apache Hop sem a necessidade de codificação;
• Configurando e conectando o Power BI e o AWS QuickSight para acesso ao banco de dados Data Warehouse;
• Elaborando o template Cloudformation para o cluster Redshift com a funcionalidade Spectrum para acesso aos banco de dados no Glue, deployando via Github Actions;
• Utilizando uma instância EC2 Linux para o controle (Scheduler) das execuções dos workflows/pipelines através do Apache Airflow;
• Utilizando Docker em 2 contextos;
○ para a execução long-lived do serviço Hop-Server que servirá como servidor para as execuções dos workflows/pipelines demandados pelo Apache Airflow; e
○ para as execuções short-lived de workflows/pipelines através do Hop-Run.
• Orquestrando e executando workflows/pipelines em containers gerenciados;
○ Elaborando o template Cloudformation para o serviço ECR e deployando-o via Github Actions;
○ Registrando a imagem docker local no repositório do ECR;
○ Elaborando o template Cloudformation para o serviço ECS e deployando-o via Github Actions; e
○ Executando e agendando à execução da task definition no cluster ECS via AWS CLI.
Depoimento de ex-participantes
Curso top com excelente conteúdo e um instrutor que manja muito do assunto...
Por Alessandro Gomes, do IBOPE
Excelente curso, Ricardo Gouvêa parabéns pelo trabalho, ótimo conteúdo abordado, obrigado...
Por Bruno Bizerra, do UOL
Mais um curso concluído, a busca por conhecimento nunca é demais...
Por Deivisson Sedrez, da Saque e Pague
O melhor treinamento que já participei...
Por Maycon Oleczinski, da Inside Sistemas
It was a tough week, going to sleep after 3:00 am, but it worthed. I've learned a lot...
Por Samuel Pinto, da Normática
Foram dois finais de semana de muito conhecimento...
Por Fabrizio Machado, da Unesc
Curso espetacular, com muitas quebras de paradigma! Melhores práticas para Data...
Por Carlos Migliavacca, da Consultiline
Excelente conteúdo e condução!...
Por Marcos Zaniratti, da ITS Group
Novos conhecimentos adquiridos...com maestria...
Por Adilson Moralles, da Fototica
Excelente conteúdo e condução!...
Por Rodrigo Marcelino, da Claro iMusic
Dinâmica do evento
Durante os encontros online ao vivo, que acontecerão nos dias 03, 05, 10, 12, 17, 19, 24 e 26 de janeiro de 2022, a partir das 19h e com duração de 2 à 3 horas no formato Online ao Vivo via Zoom, o participante acompanhará o desenvolvimento dos labs pelo facilitador e nos momentos pós aula, apoiando-se no conteúdo absorvido durante os encontros ao vivo, na gravação das aulas e utilizando o grupo de apoio no Telegram, desenvolverá os seus próprios labs alcançando desta forma um aprendizado mais eficiente.
Material
Os slides utilizados durante o bootcamp serão disponibilizados ao participante em formato eletrônico, após o encerramento do mesmo. O material cedido para o bootcamp é de propriedade intelectual da Openin Big Data. Nenhuma parte deste material e tão pouco a gravação, como também o acesso ao EaD, poderão ser cedido, emprestado ou comercializado para terceiros, nem utilizados para treinamentos e capacitações de terceiros sob quaisquer hipóteses, salvo sob autorização expressa da Openin Big Data. Caso seja identificado atitudes relatadas neste parágrafo, ações legais contra perdas e danos serão providenciadas pela Openin Big Data.
Certificado de participação
Os participantes do bootcamp receberão certificado de participação em formato eletrônico emitido pela Openin Big Data ao final do evento.

Profissional com mais de 20 anos dedicados ao desenvolvimento de projetos de Data Warehouse, Business Intelligence e Data Lake, trabalhou no principal parceiro da Business Objects no Brasil, passou pela americana Sagent (a Pitney Bowes company) como consultor pre-venda LATAM e desenvolveu ao longo deste período inúmeros projetos em empresas como Porto Seguro, Intermédica, Pfizer, Secretaria de Edução de SP, USP, Unibanco, Ambev e GPS. Atualmente é Sócio Diretor da Openin Big Data, Engenheiro de Dados AWS e Instrutor.
Política do evento
Cancelamento de pedidos pagos
Cancelamentos de pedidos serão aceitos até 7 dias após a compra, desde que a solicitação seja enviada até 48 horas antes do início do evento.
Saiba mais sobre o cancelamentoEdição de participantes
Você poderá editar o participante de um ingresso apenas uma vez. Essa opção ficará disponível até 24 horas antes do início do evento.
Saiba como editar participantesComo acessar o evento
Selecione o evento desejado e toque no botão acessar evento
Pronto! O link de acesso também será enviado para você por email.
Sobre o produtor

Openin Big Data
Somos pioneiros e referência no Brasil e América Latina há mais de 10 anos no uso das ferramentas da Suite Pentaho, trabalhando com treinamento, desenvolvimento, consultoria e suporte em projetos de Integração de Dados, Business Intelligence, Big Data, IoT e Analytics. Algumas das empresas que escolheram a Openin para alavancar seus projetos baseado em Dados: Calvin Klein, GPS, Superfrio, Linx, Totvs, TST, Atech, ClickBus, Yamaha, Prevent Senior, Porto Seguro, Globo.com, dentre muitas outras.
Métodos de pagamento
Compre com total segurança
Os dados sensíveis são criptografados e não serão salvos em nossos servidores.

Precisando de ajuda?
Acessa a nossa Central de Ajuda Sympla ou Fale com o produtor.